言語の不思議は早くから自分の頭の中にかなり根深い疑問の種を植え付けていたもののようである。六七歳のころ、始めて
今になって考えてみると、このジー、ジーという音の繰り返しは、当時の幼い頭の中に、まだ夢にも知らなかった、遠い遠い所にある、一つの別な珍しい世界からのかすかなおとずれのように響いたのかもしれない。それはとにかく、当時に感じた
英語やドイツ語とだんだんに教わるうちに、しばしば日本語とよく似た音をもった同義の語に出会う事がある。これは偶然であろうとは思っても、そのことごとくが偶然の暗合であるという事を証明する事もかなりにむつかしそうに思われた。
自分のまだ学生時代に、ある学者が、日本の神話の舞台をギリシア近辺へ持って行こうとする大胆な説を公にして問題になった事がある。自分は直接にその所説の全部を読んだわけではなかったが、その説の一部をどこかで
十年ほど前に少しばかりロシア語の初歩を学んだ事もあった。それがために「言語の不思議」に対する自分の好奇心と疑問とは、むしろ急に大きな高い階段を一つ駆け上がったような気がした。そして、一方で新しい不思議が多量に加わると同時に、他方ではこの新しい不思議が、かえって古い不思議のなぞを解くかぎとなりうる可能性を暗示するようにも見えた。それは単に
最近に至って「言語」に対する自分の好奇心を急激な加速度で増長せしめるに至った経路はあるいは一部の読者に興味があるかもしれないし、また自分が本分を忘れて、他人の門戸をうかがうような不倫をあえてするに至った事の申し訳にもいくぶんはなるかもしれないから一つの
地球物理学上の近年の問題となっている陸塊の水平移動に関する学説、俗に大陸漂移論と称するものから見た日本陸地の成立、変化、ならびにこれに連関して問題となるべき陸地の昇降、地震、火山現象等を追究するに当たって、しばしば古い過去における水陸分布の状態と現在のそれとの異同が問題となり、その一つの参考資料としていろいろな土地の地名の意義が引き合いに出る場合がある。そこで本邦地名の問題に触れるとなれば、自然の勢いで、アイヌ語や朝鮮語による地名起原説を参照しなければならぬ事になる。そうなると問題は自然自然に推移して結局は日本語の成立問題にまでも多少は触れないわけには行かなくなるのである。
そうかと言って、自分でこのような大問題をどうにかしようという非望を企てるわけにも行かないわけであるが、それでもただやみがたい好奇心から、余暇あるごとに少しずつ、だんだんに手近い隣接国民の
こういう
少し唐突ではあるが地球上における
世界じゅうの人間の元祖が一つであろうという事は単に確率論的の考察からもいちばん考えやすい事であるが、今ここで軽々しくそういう大問題に触れようとは思わない。ただ少なくも動物学上から見て同種な Homo Sapiens としての人間の世界の一部において任意の時代に発生した文化の産物のすべてのものが、時とともに拡散して行くのは、ちょうど水の中にたらした一滴のアルコホルの拡散して行く過程と、どこか類似したものであろう、という想像は、理論上それほど
昔の詩人ルクレチウスは、物質の原子はちょうどアルファベットのようなもので、種々な言語が有限なアルファベットの組み合わせによって生ずるごとく、各種の物質がこれら原子の各種の組み合わせによって生ずると書き残したが、この考えは近世になって化学式というものによっていくらか科学的に実現された。今この考えを逆に持って行くとこんな考えも起こし得られる。すなわち、まず、言語、国語という一つの体系は若干の語根元素から組成されていると仮定する。次には、この元素が化合して種々の言語や文章が組成されているが、これらの間にはその化合分解の平衡に関するきわめて複雑な方則のようなものがあると想像する。なおこれらの元素は必ずしも不変なものではなくて、たとえば
かくのごとき仮定のもとに、ある分子が時間tにおいて、距離rと、それより dr だけ大きい距離との間の地帯に達するプロバビリティは
W(r, t)dr = 1/4πDt[#「1/4πDt」は分数]e-r2/4Dt[#「2」は上付き小文字、「r2/4Dt」は分数、「-r2/4Dt」は「e」の上付き]dr
であり、中心から同時に出発した分子総数がNであれば、この時点にこの地帯に来るものの数は NW(r, t)dr である。しかしこれらの分子が放射物質のように自然崩壊をするものとすれば、この数はtについて
Ne-λt[#「-λt」は「e」の上付き]W(r)dr
であるとすべきであろう。さすれば距離rにおける密度は、これを 2πrdr で除したもので、これをσとすれば
σ(r, t) = N/8π2Drt[#「2」は上付き小文字、「N/8π2Drt」は分数]e-(r2/4Dt[#「2」は上付き小文字、「r2/4Dt」は分数]+λt)[#「-(r2/4Dt+λt)」は「e」の上付き]
で与えられる。もし中心から不断に供給が続けられていれば、これを時間tに対して積分する事になるであろう。また中心が空間的に分布されて存在すれば、さらに空間的の積分が必要になる事はもちろんである。
このような考えを実際の場合に応用して具体的の数量的計算をする事は、今のところ、不可能であり、またしいてこれを遂行しても、その価値は疑わしいものである。しかし、ただ、以上の考察の中に含まれた根本の考えがいくぶんでも実際の問題に触れたところがあるとすれば、右にあげた数式によって代表された理想的過程の内容とその結果とは、またいくぶんか実際の言語の拡散過程、ならびに時間的空間的分布の片影を
もしもこの考えがいくらか穏当である事を許容するとすれば、そこからいろいろな、消極的ではあるが、だいじな事がらが想定される。すなわちまず世界じゅうで互いに遠く隔たった二つの地点に互いに類似した言語が存在し、その中間にはその連鎖らしいものが見つからない場合があっても、それだけでは、それが必ず偶然の暗合であるとは断定されなくなる。またある甲地方の古い昔の言語が今でも存し、あるいは今はその地に消滅していて、その隣国民乙の間に現存しているという場合においても、それだけでその語が甲から乙に移入されたものだと推定する事はできなくなる。なんとならばそれはかつて甲から乙に移った事があったとしても、それが甲と前後して乙でも死滅し、ずっとあとで丙から乙に移ったかもしれないからである。そのほか分子論的拡散論において言われるようないろいろの事は言われるが、これを要するに、一つ一つの言語の分子を比べるだけでは、それだけでは歴史的の前後は決定し難いという消極的な結果になるのである。これはちょうど水中のアルコホル分子を一つ一つ捕える事ができたにしてもわれわれは到底その一つ一つの径路を判定し難いと同様である。
しかし前の考察から一条の活路が示唆される。それは、約言すれば、同系言語の「統計的密度」の「
前の算式によって示さるるごとき理想的の場合においては、一般に同種分子の密度の勾配は、ともかくも中心に対して放射的である。これはもちろん計算を待たずとも明白な事である。それでもしかりにアジア大陸のある地点からある種の分子が四方に拡散したとすれば、その系統あるいは同色の言語要素の密度は多少同心円形分布の形跡を生じてもよいわけである。たとえこの要素の等密度線がどのように変形しようとも、少なくも、その密度の傾度最大方向のトラジェクトリーを追跡して行けば、ついにはその源に到着、あるいは少なくも近づく事ができそうである。
ただ第一に問題となるのは、いかなる標準によってそのいわゆる同系要素なるものを識別しうるかという事である。これはもちろん難問題である。しかし幸いにして従来の言語学者の努力の結果は、この方法を漸進近似法(Method of successive approximation)によって進めんとする際にまず試みとして置かるべき第一近似の資料を豊富に供給してくれるのである。
この識別法を仮定すれば、次は密度の統計的計算が問題になる。前記の理想的の場合の「密度」が直接いかなる数に相応するかはこれもむつかしい問題であるが、少なくもその一つの
もちろん語根は言語のすべてではない、語辞構成や措辞法もまた言語の要素として重要である。これらをいかにして「分子」に分析するかはかなりむつかしい問題ではあるが、少なくも原理の上からはそれも不可能な事とは思われないのである。
以上のような
朝鮮語との
その後に Van Hinloopen Labberton が一九二五年のアジア協会学報に載せた論文を読んで、自分の
マライを手始めに、アイヌや、
しかしだんだんにこの調子であさって行くと、おしまいにはギリシア、ラテンはもちろん現在行なわれている西欧諸国の語にもやはり同程度の類似が認められる。またかけ離れたアフリカへんやアイスランドまでも網の目を広げられる事になってしまうのである。
具体的の例はこの序論においては省略するつもりであるが、ただ自分の意味を明らかにするために、試みに若干の例をあげると、たとえば、最も縁の遠そうな英語ですらも、しいてこじつけようと思えばかなりにこじつけられない事はない。すなわち
[#ここから表組]
beat butu
laugh walahu
flat filattai
hollow hola
new nii
fat futo
easy yasasi
clean kilei
ill walui
rough araki
hard katai
angry ikari
anchor ikari
tray tarai
soot susu
mattress musiro
etc. etc.
[#ここで表組終わり]
この程度のもの、またもっと
もっと思い切って、たとえばアフリカへ飛んで Chikaranga の
[#ここから表組]
象 zhou
魚 hove[#「v」は下線(_)付き、181-表組2行目]
鳥 shiri
咽喉 huro
[#ここで表組終わり]
などが見つかる。「象」の訓キサと似たのにはマライの gajah(サンスクリットからとある)があるが、ゾウといったようなのはずいぶん捜したがなかなか見当たりにくくて、それが、どうであろう、突然こんな意外な所に現われたのである。「魚」も同様であった。「鳥」はむしろアイヌの chiri に近いから妙である。
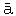 などを通してかなり東洋にも広がっているのかもしれないと想像される。もっと空想をたくましくすれば邦語のゴロなどというのも少しは怪しくなるくらいである。(鳥のアラビア語 tair. [#「t」は下点付き、182-6]
などを通してかなり東洋にも広がっているのかもしれないと想像される。もっと空想をたくましくすれば邦語のゴロなどというのも少しは怪しくなるくらいである。(鳥のアラビア語 tair. [#「t」は下点付き、182-6]こういう種類のではたとえばたっつけ
しかしこれらの例をあげたのは、決してこれらの語が邦語と因果的に関係しているという事を証明するためではなく、むしろただいかなる任意の二つの国語を取って比較しても、この種の類似がありうるものであるという事の例として取ったに過ぎない。それでたとえば、他方で「魚」や「鳥」の訓がシナ語や台湾語で説明されるとか、されないとかいう事は、ここでは問題にならないのである。
ともかくも自分の皮相的な経験によると、いかなる国語の
浜の
まず試みに、子音にのみ注目するとする。そうしてAの国語における子音の総数をnとする。次に問題をできるだけ簡単にするためにB国語の子音をもこれと同数だとする。さらにいちばん簡単な場合を考えて、各子音がそれぞれ各国語に出現する
P = s1a1b1ν + s2a2b2ν2 + s3a3b3ν3 + ……[# s、a、b に続くアラビア数字はすべて下付き小文字、νに続くアラビア数字はすべて上付き小文字]
で与えられるはずである。この中に出現するs、a、b、νの各数はともかくも統計的になんとかして求められうる性質のものである。以上はできるだけ事がらを簡単に考えた考え方である。これ以上にだんだん試験的、近似的仮定を修正して、少しずつ実際の場合に近づけて行く事も、原理上からの困難はなく、ただ次第に計算が込み入るだけである。しかし、今のところ、あまりに込み入った計算では実用にならないから、できるならば簡単な形で進みたい。
それで第一の試みとしては、まず前記のいちばん簡単な場合になるべく適合するように、材料のほうを選定し排列する事である。それはたとえば両国語の適当な語彙から比較に不適当な分子、たとえば本質的でないと思わるる接頭語、接尾語などを整理し(もちろんこれにはある仮定を要するが、それが tentative method として許容される事は、いわゆる精密科学においても同様である。そしてこの仮定には従来言語学者の苦心研究の結果が全部有効に利用されるはずである。)そうしてそれについて上記のabを出し、sは「近似的平均値」を推定して導入する。ここでいちばん困難なはABのnを同一に整理する事であるが、これにもいろいろの方法がある。たとえばA日本語とB英語の場合ならば、まず日本語のほうを、かりに「日本式ローマ字」で書く、しかして英語子音の「文字」の中で日本式にないものはかりに後者のどれかで「置換」する。たとえばcやqを皆kに直す類である。複子音も同様である。xなどは省いても、何かで置換しても統計の結果の値にはたいした影響は与えない事は明らかである。アラビアなどとなると、だいぶこの置換が困難な問題となるが、しかしたとえば
かくのごとき
siaibi[#「i」はすべて下付き小文字] = 1/4[#「1/4」は分数], i = 1, 2, 3, 4.
P = 1/4[#「1/4」は分数](1/14[#「1/14」は分数] + 1/142[#「2」は上付き小文字、「1/142」は分数] + 1/143[#「3」は上付き小文字、「1/143」は分数] + 1/144[#2つめの「4」は上付き小文字、「1/144」は分数])
1/14[#「1/14」は分数] = 0.07144444
1/142[#「2」は上付き小文字、「1/142」は分数] = 0.00510204
1/143[#「3」は上付き小文字、「1/143」は分数] = 0.00036443
1/144[#2つめの「4」は上付き小文字、「1/144」は分数] = 0.00002603
P = 0.07693694[#「P = 0.07693694」は上線( ̄)付き]÷4≒0.0192
すなわち、指定のごとき比較によって、全然偶然から来る暗合の率が約二プロセントはできる事になる。P = 1/4[#「1/4」は分数](1/14[#「1/14」は分数] + 1/142[#「2」は上付き小文字、「1/142」は分数] + 1/143[#「3」は上付き小文字、「1/143」は分数] + 1/144[#2つめの「4」は上付き小文字、「1/144」は分数])
1/14[#「1/14」は分数] = 0.07144444
1/142[#「2」は上付き小文字、「1/142」は分数] = 0.00510204
1/143[#「3」は上付き小文字、「1/143」は分数] = 0.00036443
1/144[#2つめの「4」は上付き小文字、「1/144」は分数] = 0.00002603
P = 0.07693694[#「P = 0.07693694」は上線( ̄)付き]÷4≒0.0192
しかし、上の仮定で明らかに最も不都合なのは、子音ただ一つをもつ語の割合をはなはだしく大きく見すぎた事である。これはシナ語の場合のほかには明らかに適用されない。
それで、かりに、単子音語の確率を著しく小さいとして度外視し、なお次のごとく仮定する。
a1 = b1 = 0; a2 = a3 = b2 = b3 = 4/10; a4 = b4 = 2/10[#アルファベットに続くアラビア数字はすべて下付き小文字、「4/10」「2/10」は分数]
∴ P = 4(0.16×1/142[#「2」は上付き小文字、「1/142」は分数]+0.16×1/143[#「3」は上付き小文字、「1/143」は分数]+0.04×1/144[#2つめの「4」は上付き小文字、「1/144」は分数])
= 4×0.0008756≒0.0035
すなわちわずかに〇、四プロセント弱ぐらいに減じてしまうのである。なお、もしも、シノニムの数が、上記4の二倍であるとすれば、以上の百分値はやはり二倍になるだけであるから、このほうから結果の
次に特別な場合として、邦語をかな一つ一つに切り離し、その一つ一つと音韻の似た原語と同義のシナ文字を求め、それを接合して説明をするという、普通よくあるやり方をするとどうなるか。この場合は、a1 b1[#「1」はすべて下付き小文字] いずれも1で他は零となるから
P = s1a1b1[#「1」はすべて下付き小文字]1/14[#「1/14」は分数] = s1[#「1」は下付き小文字]×0.0714
しかるにシナでは異音類義の字が多いからこの s1[#「1」は下付き小文字] が大きくなりうる。かりに s1[#「1」は下付き小文字] を5とすると、三五、七プロセントという多数の暗合を見る事になる。これはこの種の方法による比較の価値を判断する際に参考になると思う。なおこの場合に同じ漢字の発音に対して、各地方的発音の異なるものを材料として、その中から都合のいいものを採るとなると s1[#「1」は下付き小文字] がさらにいっそうはなはだしく大きくなって、結局どうでもなるという事になり、かくのごとき比較の言語学上の価値はきわめて希薄になって来る事は明らかである。次に比較の標準を少し下げて、メタセシスを許容すると、Pの展開式のi項に※[#「i」の左側と下側を線で囲った記号、187-9]が乗ぜられる事になるが(ただし子音が皆異なるとして)、これでは少なくもnがあまり小さくない限り、明らかに最後の結果の
次に、子音
1/5[#「1/5」は分数] = 0.2; 1/52[#「2」は上付き小文字、「1/52」は分数] = 0.04; 1/53[#「3」は上付き小文字、「1/53」は分数] = 0.008; 1/54[#「4」は上付き小文字、「1/54」は分数] = 0.0016
であるから a1 = b1 = 0; a2 = b2 = a3 = b3 = 4/10; a4 = b4 = 2/10[#アルファベットに続くアラビア数字はすべて下付き小文字、「4/10」「2/10」は分数] の場合でも、P = s×0.007744 となり、sが4ならば、約三、一%を得るわけである。すなわち、三分ぐらいの符合では偶然だか、偶然でないかわからない事になる。以上はもちろんかなりいろいろな無理な仮定のもとに行なった計算である。これを逐次修正して言語学者の要求に応ずるように近づけて行くことは必ずしも困難ではないが、ここではしばらくこれ以上に立ち入らない事にする。
要するにこれは、表題にも掲げたとおり、比較言語学上における統計学的研究の可能性を暗示するための一つの試みに過ぎないのである。
学者の中には、二つの国語の間の少数な
たとえば子音
統計的方法の長所は、初めから偶然を認容してかかる点にある。いろいろな「間違い」や「
それで、この方法を真に有効ならしむるには、むしろあらゆる独断、偏見、
もちろん、これも他の科学の場合と全く同様に、初めからそううまくは行かないであろう。そうして、すべての可能なるものへの試みの「不可能」を「証明」し、
余談はしばらくおいて、AB、AC、AD……の関係、なお念のために比較の主客を置換してBA、CA、DA……の関係の濃度に対するだいたいの比較的の数値を定める事ができたとすれば、少なくもここにABという一つの「鎖の輪」が、従来よりはやや科学的な根拠の上に仮設される。さすれば次には、前にAについて行なったと同様の方法を、今度はBについて行なうべきである。そうしてともかくも、BCという、「次の輪」の見当をつける。順次かくのごとくして、できるならばまた、世界の各方面から出発して、同じようにして、それぞれの鎖を――もちろんそういう鎖が存在するとの作業仮設のもとに――たぐって行く。もし多くの人の信ずるであろうごとく、この数々の鎖が世界のどこかに自然と集合すれば簡単である。さすればその焦点に集中した要素をやや確かに
しかし上に考えた鎖はおそらく一点には集中しないであろう、それがどう食い違うか、そこに最も興味ある将来の問題の神秘の殿堂の
自分はできるだけ根拠なき
思うにこの私案の第一歩の試みを最も有効に遂行するためには、おそらく言語学者と科学者との協力が必要ではないかと思われる。もしこの両者が共同し、その上に機械的の計算や統計を担当する助手の数人の力をかりることができれば、仕事はかなりおもしろく進行しそうに思われる。しかしこのほうがむしろおそらく夢のような空想であるかもしれない。
(付記) 以上の考察においては、最もこの種の取り扱いに便宜だというだけの理由から、単に「
最後に誤解のないために断わっておく必要のあるのは、従来とても統計的のやり方はあるにはあるが、単に数をかぞえて多いとか少ないとかいうだけではなんらのほんとうの統計としての意味がないという事である。全体に対する実際の符合率が偶然による符合率に対する比のみが意味をもつ、ここではそれを問題にしたという事である。
(昭和三年三月、思想)